






【HRテック】人事領域に用いられるAI~Pythonによる退職・離職予測【ランダムフォレスト、LigthtGBM】

AIはさまざまな領域で用いられている。その代表例といえるのが人事領域だ。現在のAIは、機械学習という技術に支えられている。機械学習とは、データを学習し、ルールやパターンを発見可能な技術である。この記事では、HRテックとして用いられるAIの例として退職・離職の予測を取り上げ、プログラミング言語Pythonによる実装例を紹介する。
目次
職人の判断を模倣するAI
電通が開発した「TUNA SCOPE」は、マグロの尾の写真からマグロの品質を判断するAIであり、職人の品質判断を模倣することができる。このAIを実現するための仕組みは、容易に想像できる。データとしてマグロの尾の写真と職人の判断のペアデータを十分に用意する。たとえば(画像①、良い)(画像②、悪い)、(画像③、悪い)のような具合だ。これを、コンピュータに学習させると、ある画像④を入力したとき、その良い・悪いを判断できるようになる。
このように、機械学習では、属性データと結果(良い・悪い)のデータが大量にあれば、属性データから結果を予測するAIを作ることができる。

HRテックとして活用されるAI
HRテックとは、テクノロジーを活用することで、人事領域(Human Resources)においての生産性向上や質の向上を計ることである。さきほどのマグロの品質判定と同様に考えれば、人事領域での活用方法も見えてくる。たとえば、退職する可能性のある職員の特定や、退職する職員が備えている重要属性の特定などができる。記事の後半では、このPythonコードを提示する。
AIのHRテック活用例は退職に関することだけではない。社員の属性データと「優秀・優秀ではない」というペアデータを十分に用意すれば、社員の属性データを入力して社員の「優秀・優秀ではない」をAIが判断できるようになる。また、優秀な社員が備えるべき重要属性も特定できる。
他にも、属性データから社員と配属部署の相性を予測することなども可能だ。このように、少し考えるだけでAIと人事領域の相性の良さが想像できる。
HRテックとして直接AIを用いるわけではないが、興味深いものもある。たとえば、ウェアラブル端末から社員の体調を把握するということもできる。耳たぶにつけた機械から眠気を察知したり、腕時計型の端末で血圧や心拍数などの生体データを取得したりするなど、職員の健康を守るためのHRテックも存在する。
一方で、慎重な導入が必要
ただし、AIによる学習から導き出された答えの中に、性別や出身など差別につながる属性が特性された場合には注意が必要である。たとえば、人材の評価をするなかで、「○○県出身者はパフォーマンスが低い」となった場合、「○○県出身者は採用しない」という結論を出してよいだろうか? 当然ながら否である。
このように、HRテックとしてAIを活用することには大きな展望が見込めるが、実際には慎重な導入が求められる。差別なく、公平なAIを作成することが重要だ。
Pythonによる退職・離職予測

今回使用するデータは、データ分析コンペとして最も有名な「kaggle」の「IBM HR Analytics Employee Attrition & Performance」を利用する。IBM社が作成したフィクションデータであるが、雰囲気を味わってもらえると思う。
データは年齢、給与、職場環境の満足度、月給、役職、残業の有無などの属性データがあり、Attrition(離職)を予測する。
このデータをランダムフォレストとLightGBMという人気の高いアルゴリズムで分析する。ランダムフォレストとLightGBMは決定木をベースとしたものであり、初心者でも扱いが容易だ。まずはランダムフォレストからみていこう。
ランダムフォレストによる退職・離職分析
#必要なモジュールをインポート
import numpy as np
import pandas as pd
from sklearn import ensemble
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
#CSVファイルの読み込み
df = pd.read_csv("WA_Fn-UseC_-HR-Employee-Attrition.csv")
#データ内に数値以外のデータがあるため、データ型(dtype)を数値に変換。ダミー変数化。
df_temp = []
for col in df.columns:
if df[col].dtype == 'object':
df_temp.append(pd.get_dummies(df[col], prefix=col,drop_first=True))
else:
df_temp.append(df[col])
df_conv = pd.concat(df_temp, axis=1)
#データをトレーニングデータとテストデータに分割
train, test = train_test_split(df_conv,test_size=0.2)
#データの説明変数と目的変数をセット
X_train = train.drop('Attrition_Yes', axis=1)
y_train = train['Attrition_Yes']
X_test = test.drop('Attrition_Yes', axis=1)
y_test = test['Attrition_Yes']
#ランダムフォレストをインスタンス化(実体化)
clf = ensemble.RandomForestClassifier()
#トレーニングの実行
clf = clf.fit(X_train, y_train)
#予測の実行
y_pred = clf.predict(X_test)
#正解率の算出→約86%となった
accuracy_score(y_test,y_pred)
#特徴量重要度の算出とグラフ化
feature_importances = clf.feature_importances_
importances = pd.DataFrame({"features":X_train.columns, "importances" : feature_importances})
importances_sort = importances.sort_values(by="importances",ascending = True)
fig = plt.figure(figsize=(30, 30))
ax = fig.add_subplot(1,1,1)
ax.set_title("feature inportances")
ax.tick_params(axis = "y",labelsize =30)
x_position = np.arange(len(importances_sort["features"]))
ax.barh(x_position, importances_sort["importances"], tick_label=importances_sort["features"])
fig.tight_layout()
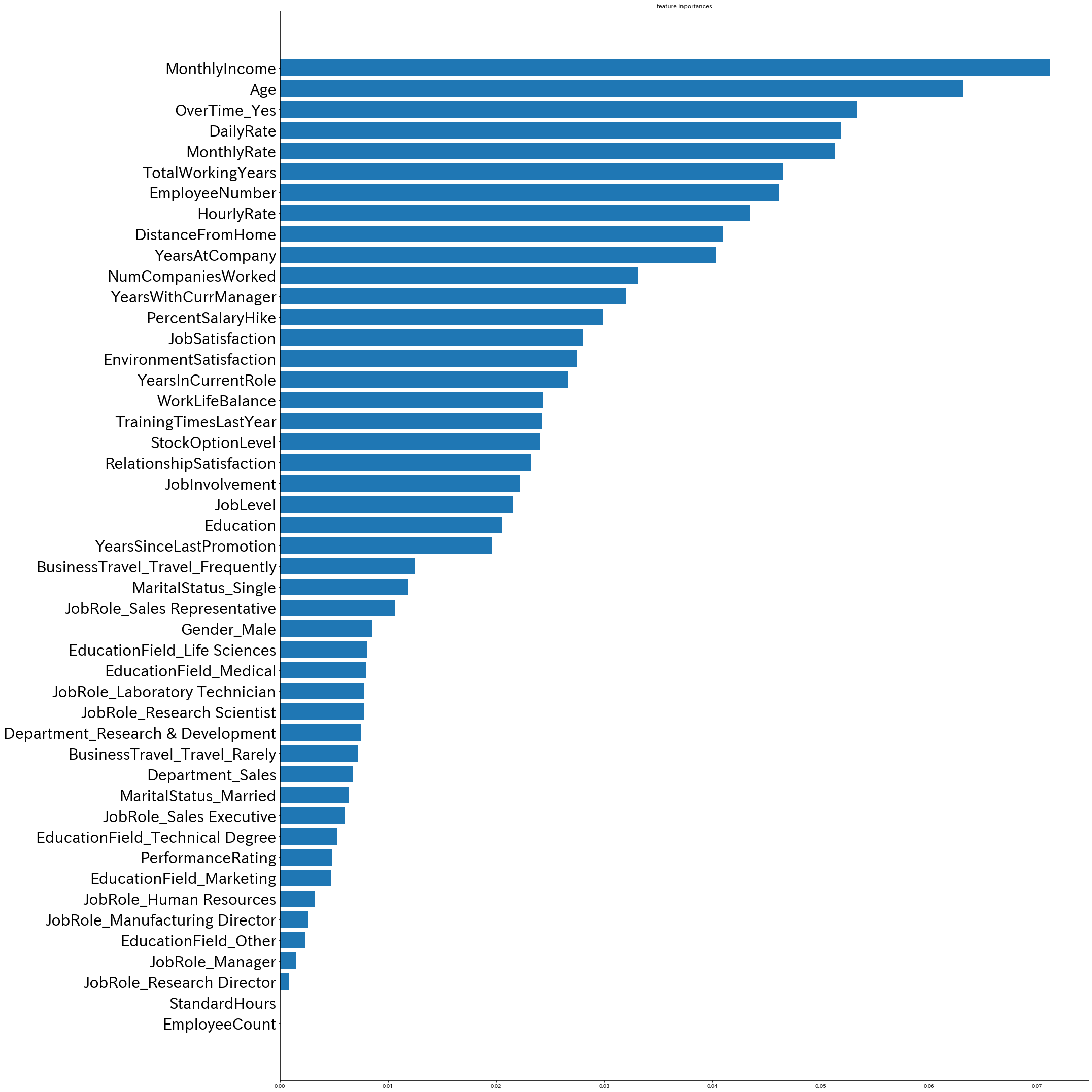
離職予測の正解率は約86%であり、離職につながる重要な特徴量は月給、年齢、残業の有無とわかった。
LightGBMによる退職・離職分析
LigthGBMはランダムフォレストと異なり、特徴量の重要度を簡単に算出できる。また、LightGBMはデータがすべて数値でなければうまく機能しない。
#必要なモジュールをインポート
import numpy as np
import pandas as pd
from sklearn import ensemble
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
#CSVファイルの読み込み
df = pd.read_csv("WA_Fn-UseC_-HR-Employee-Attrition.csv")
#データ内に数値以外のデータがあるため、データ型(dtype)を数値に変換。ダミー変数化。
df_temp = []
for col in df.columns:
if df[col].dtype == 'object':
df_temp.append(pd.get_dummies(df[col], prefix=col,drop_first=True))
else:
df_temp.append(df[col])
df_conv = pd.concat(df_temp, axis=1)
#データをトレーニングデータとテストデータに分割
train, test = train_test_split(df_conv,test_size=0.2)
#データの説明変数と目的変数をセット
X_train = train.drop('Attrition_Yes', axis=1)
y_train = train['Attrition_Yes']
X_test = test.drop('Attrition_Yes', axis=1)
y_test = test['Attrition_Yes']
#データをlgb.Datasetクラスに変換
d_train = lgb.Dataset(X_train, label=y_train)
d_val = lgb.Dataset(X_test, label=y_test)
#パラメータの設定
params = {
'objective': "binary",#二値分類
'boosting_type': "gbdt",#ブースティング
'metric': "auc"#評価基準
}
#トレーニングの実行
clf = lgb.train(params,
d_train,
num_boost_round=10000,
valid_sets = [d_train, d_val],
verbose_eval=50,
early_stopping_rounds=100)
#予測の実行
y_pred_p = clf.predict(X_test)
#予測結果が確率で算出されているため、0.5以上を1とする
y_pred = (y_pred_p> 0.5).astype(int)
#正解率の算出→約84.3%
accuracy_score(y_test, y_pred)
#特徴量重要度の算出
clf.feature_importance()
lgb.plot_importance(clf, height=0.5, figsize=(8,16))
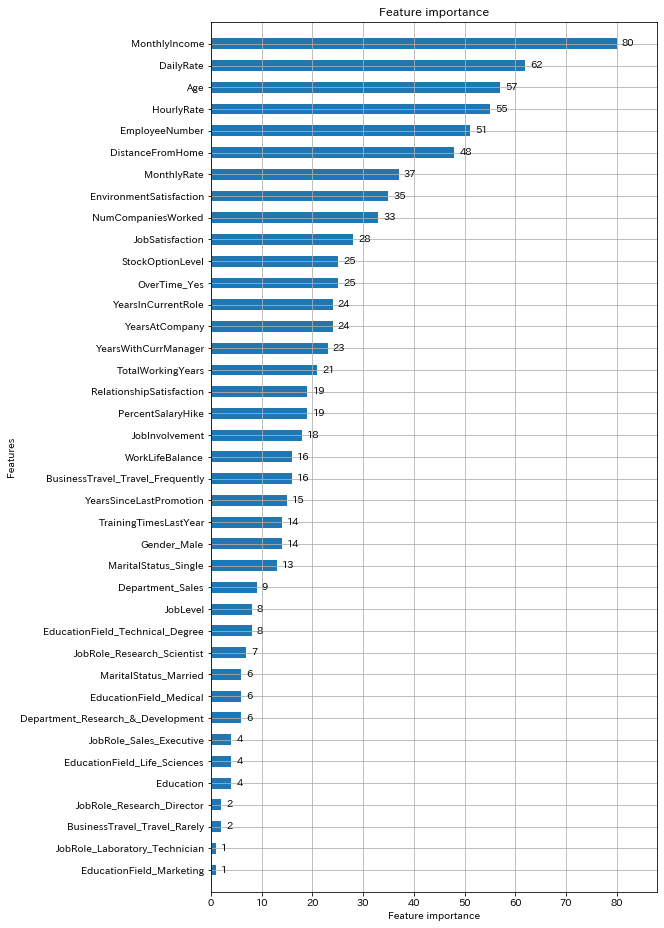
離職予測の正解率は約84%であり、離職につながる重要な特徴量は月給、日給、年齢とわかった。
今回は架空のデータであり、分析の詳細を深堀りしても意味がないため、コードの紹介にとどめる。しかし、AIにより退職・離職の予測が可能なことや、退職・離職につながる重要な属性が特定できるとおわかりいただけたのではないだろうか。
このように、AI・機械学習は人事の仕事を新たな領域へと導いてくれるものである。さらに、AIは人事領域だけでなくさまざまな領域へと応用できる可能性を秘めている。