






機械学習初心者はまず決定木とランダムフォレストを学ぼう。決定木とランダムフォレストについて学ぶことで、機械学習の理解が一気に進む。この記事では、なぜ決定木とランダムフォレストなのかを、数式などを使わず直感的に説明する。
目次
決定木とは何か?
決定木は、機械学習初心者でも非常に扱いやすいアルゴリズムだ。その名の通り、データの特徴を木のように図解できる。
決定木はホワイトボックスモデル
機械学習では、データをインプットするとアウトプットが出てくるのだが、多くの場合なぜそのアウトプットが出てきたのかわからない場合が多い。これをブラックボックスモデルという。一方、決定木は、なぜそのアウトプットが出てきたのかを説明可能なホワイトボックスモデルだ。
決定木の説明能力は高い
この説明能力の高さから、精度・性能が落ちたとしてもあえて決定木を使うということがありえる。ブラックボックスなAIを現場の人間がすんなりと受け入れることができないからだ。説明能力という点はAI開発において非常に重要である。AIを作成したときに「なぜこの予測が出てきたのか?」という質問に、「AIがそう予測したからです」としか答えられない場合、誰もがそのAIを使うことに不安を覚える。ブラックボックスなモデルでは使用する人間の説得に時間がかかり、反発も予想される。精度の高いホワイトボックスモデルはAI開発において非常に重要であり、その研究が行われている。機械学習のアルゴリズムでは、ブラックボックスなものも多く、ブラックボックスかホワイトボックスかという点はアルゴリズムの選択において非常に重要である。
決定木でタイタニック号の生存者分析う
機械学習を学ぶ人の誰もが通るのが、タイタニック号における生存者分析だ。投入するデータはExcelデータのようなものだ(下図)。機械学習に投入するデータは、所詮このようなものなので、社会人の方ならよく扱うデータ形式ではないだろうか? ビッグデータ分析とは、このExcelデータが縦にも横にも増えたデータを扱うにすぎない。だからこそ、ビッグデータ分析を過剰に恐れる必要はない。
ここでは、性別、年齢(大人か子どもか)、部屋の等級の3つのデータのうち、生還するために最も重要だった要素を特定する。そして、性別、年齢などの属性情報を、機械学習では特徴量と呼ぶ。乗客の人数は約2200人だったといわれている。
さて、このデータを決定木というアルゴリズムで分析すると、下図のような結果が出てくる。
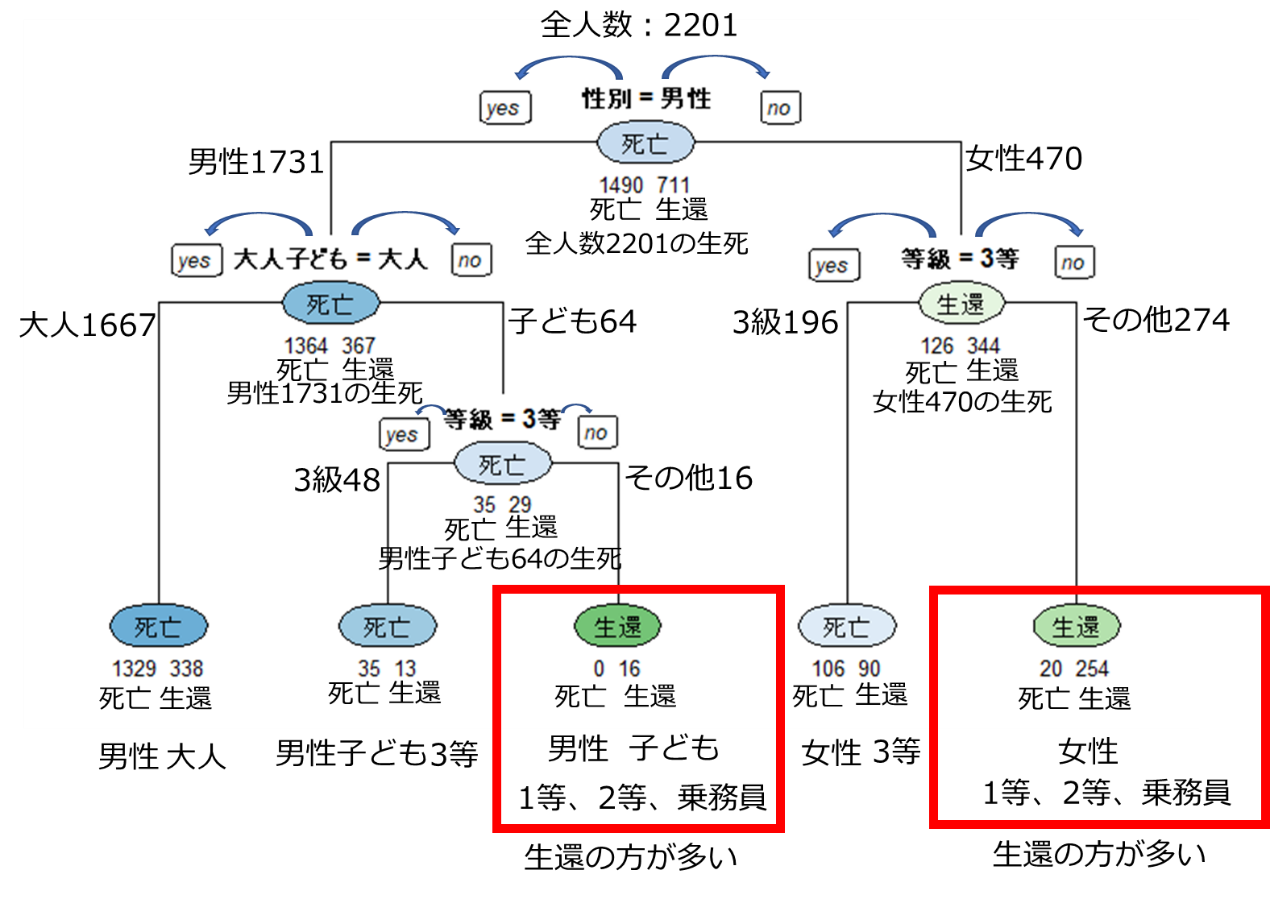
まず、一番上を見よう。全体の2201人のうち、死亡が1490人で、生還は711人となった。次に、一番上に「性別=男性」とある。つまり、決定木は性別という特徴量で分けると、生還した人と死亡したの特徴がはっきり出ると判断したのだ。つまり、生死につながった最も重要な変数は性別だったわかる。図の左側は男性のデータで、右側が女性のデータだ。男性1731人のうち、死亡は1364人で生還は367人。女性は470人のうち、死亡126人で生還は344人。男性はほとんどの人が亡くなったのだが、女性は多くの方が生還できた。

男性では性別の次に重要な特徴量は「年齢(大人か子どもか)」、女性では「部屋の等級」だった。
そして、最下段が最終的な結果だが、生還の方が多かったところを赤枠で囲ってる。生還が多かったのは、「男性かつ子どもかつ客室が3等ではない」、「女性かつ客室が3等ではない」となった。客室の等級が生死に影響したというのは、なんとも言えない気持ちになってしまう。
ただ、このデータからは、女性と子どもを優先的に避難させた大人の男性の存在が見えてくる。このように、決定木はアウトプットの解釈が可能なアルゴリズムなのだ。
決定木を他の例に応用すると、優良顧客の条件などを説明することが可能だ。多くのお金を落としてくれる顧客の重要な属性(年齢、居住地など)を特定できる。このように、決定木は説得力の高い学習方法なのだ。
決定木は扱いやすく、応用がきく
さらにありがたいことに、データをアルゴリズムに入力するときにはデータの前処理と呼ばれる作業が必要なのだが、決定木はその作業が少なくてすむ。したがって機械学習初心者にも扱いやすい。
にもかかわらず、決定木は現在も威力を発揮している強力なアルゴリズムであるランダムフォレストやGBDT(Gradient Boosting Decision Tree)の基礎となっているため、学んでおいて損はないのだ。次にランダムフォレストについて説明する。
ランダムフォレストとは何か?
ランダムフォレストとは、決定木のパワーアップ版だ。厳密にいうと、決定木を複数集めて、強力なモデルを作るということだ。専門的な言葉を使うと、決定木を弱学習器とするアンサンブル学習(複数の弱い学習器から、強力な一つの学習器を作ること)だ。パワーアップとはどういうことかというと、ランダムフォレストは決定木の長所を生かしつつその短所を克服しているのだ。
4つの観点で決定木とランダムフォレストについて考える
以下の4つの観点から、決定木・ランダムフォレストについて見ていく。
①バイアスとバリアンス
②前処理の煩雑さ
③ハイパーパラメータの数
④特徴量重要度の確認
①バイアスとバリアンス

機械学習を利用する者が、必ず知っておかなければならない言葉がある。それがバイアスとバリアンスという名の誤差だ。この言葉を知っていれば、いっきに機械学習の理解度が上がる。
データとあなたが構築した予測モデルの誤差は、以下のように表現できる。
誤差=バイアス+バリアンス+ノイズ
まず、簡単に用語の意味を説明し(読んだだけではわからないと思われる)、後で直感的な解説をする。
バイアス・・・モデルの表現力(特に線形・非線形)に由来する誤差
バリアンス・・・訓練データの選び方に由来する誤差(異なる訓練データへの対応力)
ノイズ・・・本質的に消せない誤差
ノイズは消せないのだから、考慮する必要がない。注目すべきはバイアスとバリアンスだ。バイアスとバリアンスの違いを理解するには、線形と非線形という言葉を知っておくのがベストだ。数学嫌いの人はここで嫌悪感を持ってしまうかもしれないが、難しい話は出ないので勇気を持ってついてきてほしい。なんのことはない。
線形→データを直線(平面)で近似
非線形→データを曲線(曲面)で近似

図の太線を見てほしい。非線形のモデル(右図)は表現力が高いため、データにフィットしたモデル構築が可能だ。非線形モデルのほうが、データとモデルの誤差が小さい。
このようなとき、
非線形モデル→バイアスが小さい
線形モデル→バイアスが大きい
という。この図だけを見ると、「非線形の方が明らかに予測精度の高い良いモデルだ」と思う人もいるだろう。ところが、ことはそう単純ではない。上の図の訓練データを少し変えてみよう。

いかがだろうか?線形モデルでは、形状は大きく変わらない。一方、非線形モデルでは、形状が大きく変わってしまった。そう、非線形モデルは「データにフィットし過ぎている」のだ。違う言葉で述べると、「データが少し変わると、モデルの形状が大きく変わってしまう(予測結果が大きく変わる)」ということだ。
このようなとき、
非線形モデル→バリアンスが大きい
線形モデル→バリアンスが小さい
という。多少データを追加もしくは削除しても、線形モデルの形状は変わらない。ここに線形モデルの強みがある。以上をまとめると、一般に、
非線形モデル→バイアスは小さいが、バリアンスが大きい
線形モデル→バイアスは大きいが、バリアンスは小さい
線形・非線形どちらのモデルも一長一短がある。機械学習アルゴリズムを使う際は、今使っているモデルのバイアスとバリアンスの大小を知っておかねばならない。これが機械学習モデルの選択に関する重要な示唆を与えてくれる。線形か非線形かは常に理解しておくべきで、非常に有名なディープラーニングというアルゴリズムは非線形だる。
ランダムフォレストの戦略
ここでようやく決定木に戻ろう。実は、ランダムフォレストに使われている決定木も、非線形モデルだ。つまり、バイアスは小さいという長所がある反面、バリアンスは大きいという短所がある。
ランダムフォレストのメリットは、このバリアンスを小さくできることにある。つまりランダムフォレストは「バイアスが小さく、バリアンスも小さい理想的なモデル」なのだ。ランダムフォレストでは決定木をたくさん作り、最終的には多数決のような形で予測を出す。
そして、ランダムフォレストでなぜバリアンスが減るかというと、以下2つの理由による。
①決定木を作る際にすべての訓練データを使わずに、一部の訓練データのみを使う
②決定木を作る際にすべての特徴量を使用せず、決めた数の特徴量のみ使用する。
以上①②より、「少々の訓練データの変更では結果が変わらないモデル」、つまり「バリアンスの低いモデル」ができる。
ランダムフォレストに代表されるバギングというアンサンブル学習(複数の弱い学習器から強力な一つの学習器を作り出す)は、「バリアンスを下げる」ための戦略だ。ここで一つ覚えておくといいのだが、バリアンスが最初から小さい線形モデル(よく知られている重回帰分析などのモデル)は、バギングというアンサンブル学習には向かない。
アンサンブル学習からわかる、世界は複雑にできているという可能性

最も有名な機械学習コンペであるKaggleでは、このアンアンブル学習が頻繁に用いられている。そして、さまざまなモデルを組み合わせるスタッキング(アンサンブル学習の一種)がブームとなって久しい。「複雑なモデルの方がより精度が高くなる」ということが起きている。「物事の本質はシンプルな言葉で表現できる」というのが私の信念だが、普通に考えて、世界はそう簡単な構造をしていないのだろう。機械学習初心者には、複数のモデルを組み合わせる「アンサンブル学習」というものがあると知っておいてほしい。よく使われるアンサンブル学習は、以下の3つだ。決定木の文脈でざっくりと述べると、
①バギング→複数の決定木を用いる
②ブースティング→1つの決定木の誤差に注目し、その誤差を減らすために学習を何度も行う
③スタッキング→決定木だけでなく、いろいろなモデルを組み合わせて予測を行う
ランダムフォレストは決定木のバギングだが、決定木のブースティングとしてGBDT(Gradient Boosting Decision Tree)が知られている。GBDTは非常に高い精度が出せるとして注目を浴びており、XgBoostやLightGBM、Catboostがよく知られていて評判の良いアルゴリズムだ。ちなみに、ブースティングアンサンブル学習は機械学習への理解を深めていくうえで必ず知っておくべきものである。
以上では、なぜ機械学習初心者がランダムフォレストを使用するべきかということを、①バイアスとバリアンスの観点から説明した。
ここからは、機械学習初心者にランダムフォレストを推奨する理由を、
②前処理の煩雑さ
③ハイパーパラメータの数
④特徴量重要度の確認
の観点から説明する。
②前処理の煩雑さ

「Garbage In Garbage Out」(ゴミデータからはゴミのような結果しか得られない)という機械学習の重要な鉄則がある。多くの場合、たとえ大量のデータを保有していたとしても、データの前処理をせずに学習すると芳しい結果を得られないことがある。実は、どの機械学習アルゴリズムを選択するかよりも、データの質や特徴量選択の方が結果に影響を与える場合が多い。データサイエンティストの腕の見せどころは、この前処理である。
最近、「前処理の自動化に成功した」という発表がよく行われているが、「完全自動化」はなかなか難しいのではないかと私は思っている。「どんなデータを使おうか」ということに関して人間の知識が必要となる。たとえば、屋台で売っているアイスクリームの売上を予測するとして、どんなデータが必要だろうか? 気温や降雨量、立地などの情報が必要だろうと推測できるが、どんなデータが必要化に関しては人間が考えなければならないし、ときにそのビジネスに詳しい専門家の知見が必要となる。
前処理の一つに「標準化」(特徴量の平均をゼロ、分散を1にする処理)という単位変換の工程がある。多くの機械学習アルゴリズムがこの標準化という過程を必要としている。標準化とは単位をそろえることだ。たとえば、身長と体重という2つのデータは単位が異なっていて比較が困難だ。171cmと60kgでは、1cm、1kg増えたときのインパクトが異なる。標準化は単位をそろえることで、1単位データが増えたり減ったりする影響を同じにできるのだ。そして、この標準化を行っていないと、予測結果に多大な影響を与えてしまうことがある。
しかしありがたいことに、決定木もランダムフォレストも特徴量の単位に影響されないアルゴリズムのため、標準化を必要としない。前処理に対する理解の浅い機械学習初心者にとっては、必要なステップが減るため利用しやすいのだ。
③ハイパーパラメータの数

ハイパーパラメータというと、仰々しい名称だが、要するに「人間が数値を設定する必要がある」パラメータのことだ。どんな機械学習アルゴリズムも、複数のハイパーパラメータに値を設定しなければならない。ディープラーニングに代表される高度なアルゴリズムには、多数のハイパーパラメータが存在する。このハイパーパラメータの設定は、ある意味職人芸なのだ。ところが、ランダムフォレストの基本的なハイパーパラメータはたった2つしかない。
①作成する決定木の本数
②個々の決定木に使用する特徴量の数
つまり、何本の決定木を作るかと、1本の決定木に何個の特徴量を使うかという情報のみを与えればいいということだ。
この2つだけなら、機械学習初心者でも扱いやすいはずだ。
④特徴量重要度の確認
タイタニック号における生存分析により重要な特徴量が性別とわかったが、決定木では重要な特徴量を知ることができた。そして、ランダムフォレストも同様に、特徴量の重要度を算出することができる。つまり、「なるほど、この予測結果になったのはこの特徴量が効いているんだな」のような理解が可能となるのだ。解釈可能なアルゴリズムは非常に重宝される。
ここまで、決定木とランダムフォレストに関して以下4つの観点から考察した。
①バイアスとバリアンス
②前処理の煩雑さ
③ハイパーパラメータの数
④特徴量重要度の確認
これら4つは、サポートベクターマシンや他の機械学習アルゴリズムに関しても有効な視点となる。大事なことは、「他の人が使っているから」や「なんとなく」という理由ではなく、明確な根拠を持ってアルゴリズムを選択することだ。それぞれのアルゴリズムに長所・短所がある。決定木とランダムフォレストなら「初心者でも扱いやすく、ホワイトボックス」という点がメリットだ。決定木とランダムフォレストを学ぶ過程で多くのことが学べたはずだ。ぜひこれからも学習を継続していただきたい。
決定木とランダムフォレストのプログラミング言語Pythonによるコード例は、以下の記事で行っている。興味のある人はそちらもぜひ確認してみてほしい。
・決定木↓

・ランダムフォレスト↓