目次
サポートベクターマシンとは?
サポートベクターマシンはSVM(Support Vector Machine)とも呼ばれる機械学習のアルゴリズムです。特に2000年~2010年頃までは非常に注目されており、ディープラーニングが登場する前はとても人気のあるアルゴリズムでした。
分類だけでなく、サポートベクターレグレッション(SVR)という回帰の手法としても使えます。ちなみに回帰とは、数値を予測することです。この記事の後半でPythonによるSVM,SVRのコード例を紹介します。
SVMの人気を奪い去ったディープラーニングとは?
ディープラーニングは、脳のニューロンの仕組みを模したモデルであるニューラルネットワークを基礎としています。サポートベクターマシンは高い精度を誇るものの、ビッグデータと呼ばれる大規模データを扱うことに問題を抱えていました。ビッグデータをうまく扱えるディープラーニングが、現在最も精度が高いものとして知られています。とはいいつつも、常にビッグデータを入手できるはずもなく、それほど多くないデータの場合にはディープラーニングよりも精度が出ることも多いです。サポートベクターマシンを知っていて損はありません。
サポートベクターマシンが高性能な理由
サポートベクターマシンのメリットは、マージン最大化とカーネル法による汎化性能の高さです。機械学習では汎化性能を考えることが重要であり、汎化性能とは「訓練データではない未知のデータへの対応力」を意味します。つまり、未知のデータへの対応力が高いところがサポートベクターマシンのメリットです。

サポートベクターマシンは高度な数学理論に基づいているため、ここでは概略だけを述べます。
マージン最大化とは?
まず、マージン最大化とは、分類をするのに「ギリギリを狙わない」ということです。つまり、下図破線ようなギリギリの分類ではなく、太い実線のような2つのグループの両方ともから離れている分類を目指すということです。
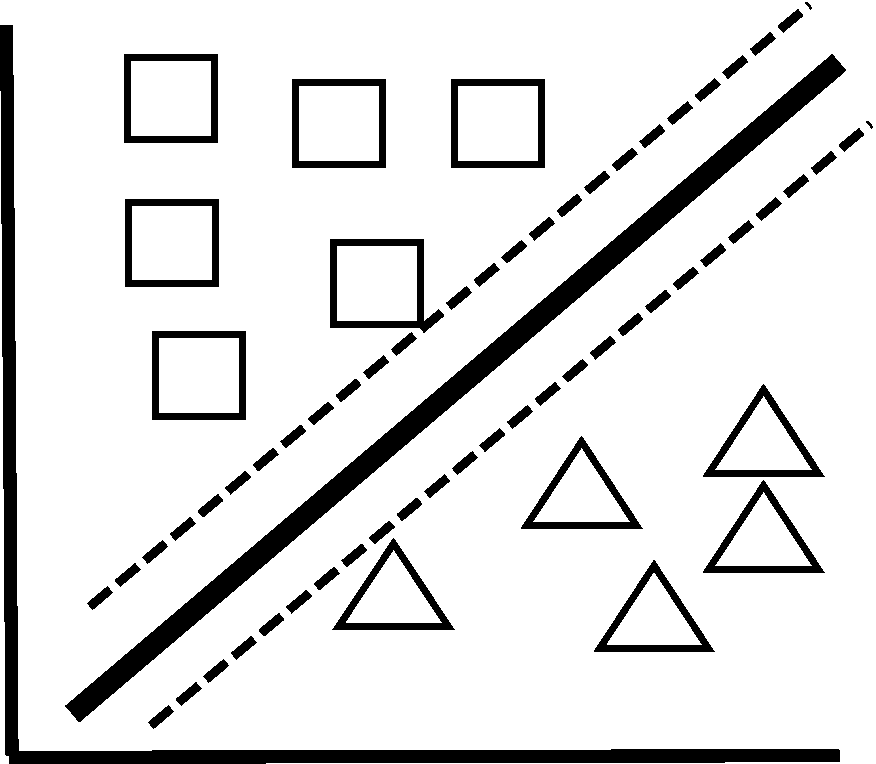
破線と接している四角と三角のデータがありますよね? これらデータが少し変動すると、破線を越えてしまいます。マージン最大化(実線)では、少々データが変動したとしても分類に影響がありません。そのため、汎化性能が高くなるのです。
カーネル法とは?
次にSVMの2つ目のメリットであるカーネル法について説明します。カーネル法は、「そんなことが可能なのか!」と思えるような魔法じみた手法です。下図のようなデータがあるとします。
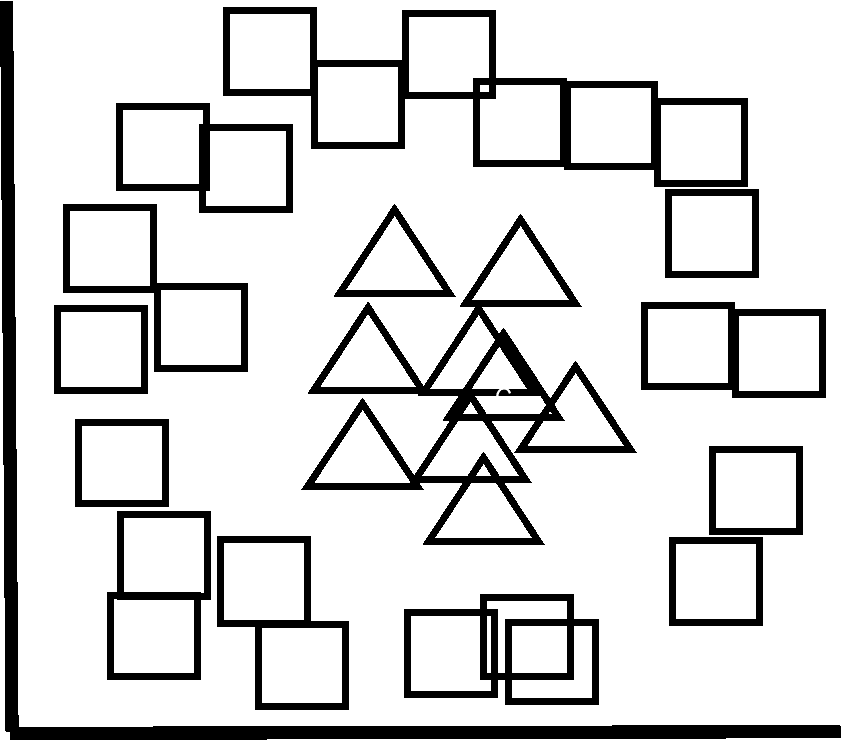
機械学習アルゴリズムは線形・非線形の区別が重要ですが、サポートベクターマシンは基本的に線形のアルゴリズムです。つまり、直線などでデータを分類します。したがって、図の三角と四角は直線でうまく分離できませんよね。そこで、上図の2次元データ(平面)を、3次元などの高次元空間へと次元拡張(変換)します。すると、下図のように三角と四角は平面(直線の次元を1つ上げたもの)で線形分離(直線や平面などでデータを分類)できそうですよね。
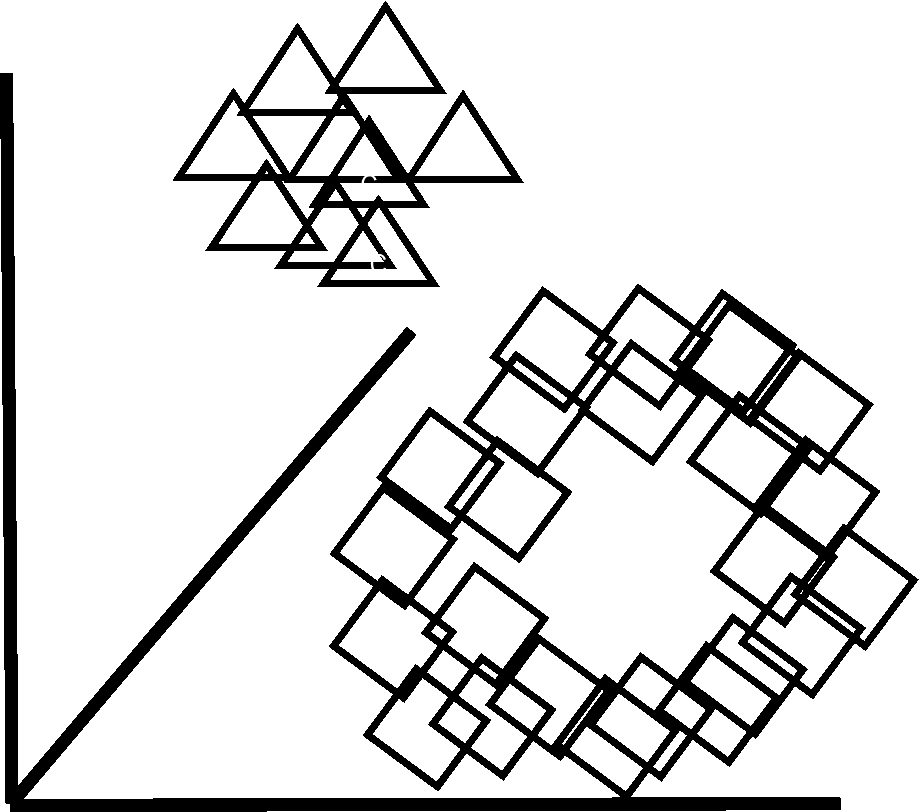
「2次元平面上ではきれいに分離できないから、3次元空間に変換して線形分離する」のような興味深いテクニックです。しかし一般に、こうした次元拡張を行うと計算量が膨大かつ困難になってしまいます。そこでカーネル関数(ガウシアンカーネルなど)というものを導入すると、その困難な計算を回避できるのです。
無限次元空間への拡張という狂気

実は、高次元になればなるほどうまい線形分離を発見しやすくなるのですが、よく利用されるガウシアンカーネルを用いると、なんと事実上無限次元空間への拡張が可能となります。それでいてカーネル法は、無限次元という超高次元に拡張していることを意識させず、しかも超高次元の計算を隠した状態で同等の効果を得ることができるのです。あまりに都合が良すぎるため過学習の懸念がありますが、さきほどのマージン最大化がうまくブレーキの役割りを果たしており、汎化性能の高いモデルとなります。
常にディープラーニングを使えるわけではない
以上のマージン最大化とカーネル法により、SVMは性能の良い強力なアルゴリズムとして知られています。しかし、ビッグデータと呼ばれる大規模データに対してはサポートベクターマシンの計算量が膨大となるため、あまり用いられない傾向にあります。こうして、ビッグーデータ全盛の現在では、ディープラーニングなどの手法がよく利用されている形になります。ただ、「だったらディープラーニングだけを使えればいい」というのは誤解です。データ量が少ないときにはサポートベクターマシンの精度がディープラーニングを上回ることは十分ありえます。
【分類コード例】サポートベクターマシンによるワインの品質評価予測
今回の例ではscikit-learnというAI作成に非常に役立つPythonライブラリーを使用します。scikit-learn内に、練習用として使えるワイン品質評価データがありますのでそれを使用します。ワインの色やポリフェノールの量などから、専門家のワイン品質評価を模倣するAIを作成します。
学習の際には標準化という処理を行います。標準化とは、データの単位を揃えることです。たとえば、身長と体重では、180cm、70kgと単位が違いますよね。身長と体重が1増えることによる影響は、身長と体重で大きく異なります。サポートベクターマシンなど多くのアルゴリズムは、データの単位が揃っていることが前提となっているので、今回は標準化を行っておきましょう。また、scikit-learnでサポートベクターマシンを使う際には、SVMではなくSVCというものを使います。CはClassification(分類)という意味です。回帰の場合はSVRを用います。
ちなみに、標準化を行わずに学習を行うと、専門家の予測とAIの予測の一致率は約78%でした。標準化をすると、精度はどれくらい上がるでしょうか? 以下に標準化を行った場合のコード例を記載します。
#必要なモジュールをインポート from sklearn.svm import SVC from sklearn.preprocessing import StandardScaler from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score #scikit-learn内にあるワインの品質判定用データセットをwineという変数に代入。 wine = load_wine() #Xにワインの特徴量を代入。特徴量は、ここではアルコール濃度や色などwineの属性データのこと。 X=wine.data #yにワインの目的変数を代入。目的変数は、ここでは専門家によるワインの品質評価結果のこと。 y=wine.target #トレーニングデータとテストデータに分割。 #トレーニングデータで学習を行い、テストデータでAIが実際に使えるかの精度検証。テストデータは全体の3割に設定。 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) #標準化を実行するためのStandardScalerをインスタンス化(実体化)。fitで訓練データを標準化する際の準備。 scaler = StandardScaler() scaler.fit(X_train) #サポートベクターマシンをインスタンス化(実体化)。 回帰の場合はSVR()。 clf = SVC() #transformで標準化を実際に行い、そのデータに対してサポートベクターマシンによる学習を行う clf.fit(scaler.transform(X_train), y_train) #テストデータにも標準化を実行し、predict(予測)を行う y_pred = clf.predict(scaler.transform(X_test)) #正解率の算出。予測データと正解データを比較してAIの精度検証を行う。 accuracy_score(y_test,y_pred) #専門家とAIの予測の一致率は100%となった
AIの予測精度が100%となりました。標準化前は約78%だったので大幅な精度向上となりましたね。しかし、高すぎる精度は逆に不安になります。「今後、100%の精度が出る」とは思わないほうがよいです。
【回帰コード例】サポートベクターレグレッションによるボストン住宅価格予測
今回は、scikit-learn内にあるボストンの住宅価格データを利用しましょう。犯罪の発生率や部屋数、高速道路までのアクセスの良さなどの特徴量(属性データ)と住宅価格がわかっています。特徴量情報から住宅価格を予測するAIを作成しましょう。SVMとほぼ同様のコードとなります。
#必要なモジュールをインポート from sklearn.svm import SVR from sklearn.preprocessing import StandardScaler from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split #scikit-learn内にあるボストンの住宅価格データセットをbostonという変数に代入。 boston = load_boston() #Xに住宅の特徴量(属性データ)を代入。特徴量は、ここでは犯罪率、広さ、部屋数など。 X=boston.data #yに正解データとなる住宅価格を代入。 y=boston.target #トレーニングデータとテストデータに分割。 #トレーニングデータで学習を行い、テストデータでAIが実際に使えるかの精度検証。テストデータは全体の3割に設定。 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) #標準化を実行するためのStandardScalerをインスタンス化(実体化)。fitで訓練データを標準化する際の準備。 scaler = StandardScaler() scaler.fit(X_train) #サポートベクターレグレッションをインスタンス化(実体化)。 reg = SVR() #transformで標準化を実際に行い、そのデータに対してSVRによる学習を行う reg.fit(scaler.transform(X_train), y_train) #テストデータにも標準化を実行し、predict(予測)を行う y_pred = reg.predict(scaler.transform(X_test)) #回帰モデルの評価の目安となる決定係数を表示(1に近いほどモデルの当てはまりが良い) print(reg.score(scaler.transform(X_test),y_test))
決定係数は0.55となりました。決定係数は1に近いほどモデルの当てはまりが良いため、標準化を行うだけでは精度が十分に出ませんでした。ただ、SVRのコードがSVMと同様だとわかっていただけたと思います。
まとめ
ここまでサポートベクターマシンの概略とコード例を紹介してきました。scikit-learnではサポートベクターマシンにかかわらず、今回のコードとほぼ同様に決定木などさまざまなアルゴリズムを適用することができます。そのため、どうしても個々のアルゴリズムの中身に関しての学習がおろそかになりがちです。しかし、個々のアルゴリズムの特徴やメリット・デメリットを理解しないと、良いAIを作ることは不可能です。ぜひこれからも表面的なコードだけでなくより深くAI・機械学習への理解を深めていってください。
ここまで長文をお読みいただきありがとうございました。またお会いしましょう!