


この記事は、人工知能(AI)がどのような仕組みでできているかのイメージを持てることを目的に執筆している。特に、AIや機械学習を学び始めた初学者に向けて書いている。まとめとして記事の最後に、ワインの品質予測を行うプログラミングコード例を記載している。今回はランダムフォレストというアルゴリズムを使用する。
機械学習は、現在のAIを支えている主要な技術であり、データから自動的にルールやパターンを発見することができる。「うちの会社の顧客の重要属性は居住地である」とか「沈没したタイタニック号で生き残るために必要な条件は性別だった」「ワインの品質を予測する重要な要素は気温だ」など、データを入力すると自動的にルールを発見してくれる。大量のデータを安価に利用できるようになった現在、機械学習は非常に注目されている。
現時点でAIと機械学習は同じ文脈で語られることが多い。この記事では、AIと機械学習を同等のものとしてイメージしてもらって問題ない。
目次
少ないコードで誰でもAIを作れる時代の到来
AIを開発するために用いられる最も人気のあるプログラミング言語がPythonである。Pythonはさまざまな用途に利用可能な汎用プログラミング言語であるため、AI以外にも使用できるのが利点だ。さらに文法もシンプルなため、これからプログラミング始めようと思っている人に適した言語だといえる。
そのPythonでは、scikit-learnという機械学習を簡単に行うことができる便利なライブラリーがある。たった数行のコードを書くだけでAIを作ることができるのだ。scikit-learn以外にも、PythonにはAIを作るための便利なライブラリーが多数存在しており、近年非常に人気の高いプログラミング言語である。本記事の最後でそれを実演したい。

AI・機械学習の内部では何が行われているのか?
簡単にコードを書けてしまうというのは、メリットでありデメリットでもある。デメリットは、理論を理解していない人でも複雑な計算を実行可能になってしまうことだ。実際は複雑な計算を行っているにもかかわらず、「なんだ、AIを作ることは簡単じゃないか」と良くも悪くも誤解してしまう。ただ、内部の仕組みを理解しないことには、結局は高精度のAIを作ることはできない。さらに、内部の状況がわからないと、「怖くてAIを使えない」という事態に陥る場合がある。人間がAIを信用できないのだ。
2次関数で理解できるAI・機械学習の学習の仕組み
AIの学習イメージを持ってもらうため、架空の例を出そう。つまらない例で恐縮だが、架空のアイドルユニット「ショコラボーン」がデビューシングルのCDを発売したとしよう。週ごとの売上が以下のようになったとする。
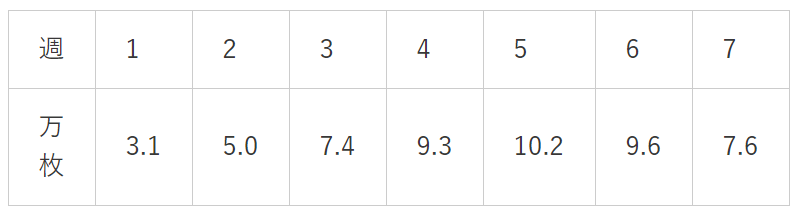
これをプロットすると、
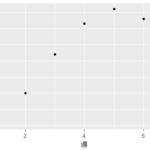
形を見ると、数学の授業で習った2次関数(放物線)のように見える。実際に2次関数で近似してみよう。
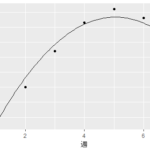
さて、2次関数は一般に、
$$ax^{2}+bx+c$$
と書ける。ここで行った近似は、2次関数の係数a,b,cという数値(これをパラメータと呼ぶ)を求めることだ。私は今、CDの売上を2次関数で近似したのだ。
この関数を使って、CDの売上予測ができることになる。
機械学習とパラメータ

この2次関数の例がイメージできると、機械学習の仕組みが同様に理解できる。機械学習が行っていることは、a,b,cのような数値(パラメータ)を求めているだけなのだ。そして、重要なことだが、機械学習のパラメータには次の2種類がある。多くの人が誤解しやすいポイントであり、これを知ればAI・機械学習の仕組みのイメージが湧くはずだ。
①ハイパーパラメータ
②学習(トレーニング)で最適化するパラメータ
ハイパーパラメータは、機械学習のトレーニングを実行するために人間が自分で設定しなければならないパラメータだ。
学習(トレーニング)により最適化するパラメータは、文字通り長い時間をかけてコンピュータが学習するパラメータである。この学習により最適化するパラメータは「重み」と呼ばれることが多い。
おおざっぱなイメージであるが、さきほどの2次関数でいうと、ハイパーパラメータは「3次関数でも4次関数でもなく2次関数で近似しようとするときの2」であり「a,b,cが学習で最適化するパラメータ」のような具合だ。
ただ、実際にはハイパーパラメータも、予測がうまくいくよう学習を実行しながら調整していくことになる。
scikit-learnとランダムフォレストによるワインの品質判定
scikit-learnには、ワインの品質判定に使えるデータを用意されている。これを使用して機械学習プログラミングのイメージを持とう。今回は、ランダムフォレストという初心者でも使いやすくある程度の精度を見込めるモデルを使用する。ランダムフォレストは、決定木というモデルがベースになっている。決定木だけでも予測を行うことが可能であり、その決定木をたくさん用意してそれぞれ予測を行い、最終的に多数決のような形で予測結果を決めるのがランダムフォレストだ。木をたくさん用いるからフォレスト(森)という名称が用いられている。決定木とランダムフォレストの詳細に関しては、以下の記事を参考にしてほしい。この記事では詳細な理解がなくとも問題ない。

それではワインの品質判定を行うコードをいかに記載しよう。詳細は理解できなくてもよいので、たった数行でAIを作ることができる点に注目してほしい。何を行っているかというと、ワインの専門家の品質評価から学習し、ワインの品質判定を自動で行うAIを作成することである。ワインの品質を自動的に予測できるAIが簡単に作れるのだ!scikit-learnの素晴らしさがここにある。決定木やランダムフォレストでは前処理をあまりしなくてもある程度精度が出るため、あえて前処理を行わずにストレートに学習を実行する。
#必要なモジュール(便利な機能)をインポート from sklearn import ensemble from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score #scikit-learn内にあるワインの品質判定用データをwineという変数に代入。 wine = load_wine() #Xにワインの特徴量を代入。特徴量は、ここではアルコール濃度や色などwineの属性データのこと。 X=wine.data #yにワインの目的変数を代入。目的変数は、ここでは専門家によるワインの品質評価結果のこと。 y=wine.target #トレーニングデータとテストデータに分割。 #トレーニングデータで学習を行い、テストデータでAIが実際に使えるかの精度検証。テストデータは全体の3割に設定。 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) #ランダムフォレストをインスタンス化(実体化)。n_estimatorsは1000本の決定木を用いるというハイパーパラメータ。 clf = ensemble.RandomForestClassifier(n_estimators=1000, random_state=1) #学習(トレーニング)を実行し、「重み」と呼ばれるパラメータを求める。 clf.fit(X_train, y_train) #テストデータを用いてpredict(予測)を実行 y_pred = clf.predict(X_test) #正解率の算出。予測データと正解データを比較してAIの精度検証を行う。 accuracy_score(y_test,y_pred) #予測精度は約98%となった。つまり、作成したAIは専門家の予測と約98%一致した。
特に、ここでは以下のコードに注目しよう。
#ランダムフォレストをインスタンス化(実体化)。n_estimatorsは1000本の決定木を用いるというハイパーパラメータ。 clf = ensemble.RandomForestClassifier(n_estimators=1000, random_state=1)
ランダムフォレストでは、たくさんの決定木を用いるが、何本の決定木を作るかという数字がハイパーパラメータである。これは人間が数字を決めてあげないといけない。100本なのか1000本なのか、何本の決定木を作るかを決める。ここでは1000本の決定木を作ることにした。つまり、イメージは1000本の決定木でそれぞれ予測を行い、最終的に多数決に近い形で予測結果を確定させるのだ。
次に、以下のコードにも注目する。
#学習(トレーニング)を実行し、「重み」と呼ばれるパラメータを求める。 clf = clf.fit(X_train, y_train)
機械学習には2つのパラメータがあり、人間が設定するハイパーパラメータと学習(トレーニング)により求めるパラメータ(重み)がそうであった。
fitというメソッドで「重み」パラメータを計算しているのだ。
つまり、行っていることは先程の2次関数による近似と同じである。
まとめ
AI・機械学習の仕組みは、高校生レベルの知識で十分に理解が可能だ。何度も述べているが、機械学習が行っていることは、モデルのパラメータを求めるという作業である。パラメータには、学習を実行するために人間が設定するハイパーパラメータと、学習で求めるパラメータ(いわゆる「重み」)の2種類がある。そうしてモデルのパラメータを求めてあげると、ワインの専門家の評価を模倣するAIが作れるのだ。
以上が、AI・機械学習の内部で行われている学習の仕組みである。今回はランダムフォレストというものを利用したが、他のアルゴリズムでも基本的にはまったく同じである。サポートベクターマシン、ディープラーニングなどさまざまなものがあるが、結局は「ハイパーパラメータを設定して学習を実行し、重みを求めてAIを作る。そしてそのAIを用いて予測を行う」ということだ。これからもAI・機械学習を怖れずに学習を進めてほしい。