



目次
圧倒的に利用されているレコメンドエンジン
世界的ECサイト「Amazon.com」で買い物をしていると、「この商品を買った人はこんな商品も買っています」という表示をよく見かけます。筆者もよくこの仕組で提案された商品をAmazon.comで購入しています。確かに、自分がほしい商品に近いもの提案してくれているように感じます。
このような仕組みの実現に用いられているのが、協調フィルタリングという技術です。協調フィルタリングは、類似度に基づいておすすめの商品を提案します。ユーザーの嗜好(購買傾向)の類似度に基づいて商品をレコメンド(推薦)することをユーザーベース、商品の類似度に基づいてレコメンドすることをアイテムベースと呼びます。商品の類似度のイメージはつきやすいと思いますが、ユーザー嗜好の類似度のイメージがわきづらいと思いますので下図を見てください。
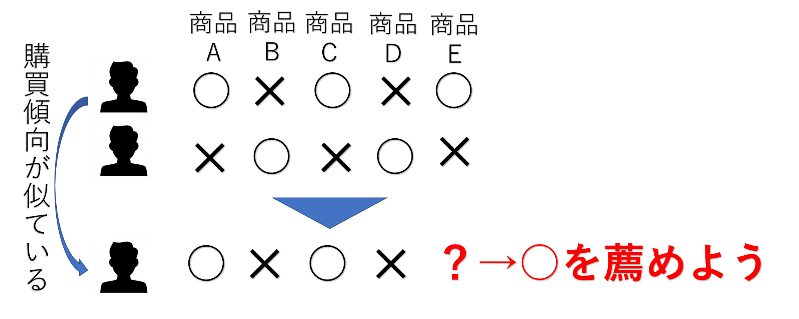
購買傾向が似ている人のデータを参考にして商品を提案するという仕組みです。確かに購買につながりそうですよね。
ユーザーベースとアイテムベースのメリット・デメリット
ユーザーベースのレコメンドでは、個々ユーザーの嗜好に合わせた商品を提案できる反面、購買履歴のない新規ユーザーや誰にも購入されていない新商品への対応ができません。

逆に、アイテムベースのレコメンド(推薦)では、購買履歴のない新規ユーザーに対しても商品の提案ができる一方、すべてのユーザーに同じ商品が提案されます。
ちなみに、類似度を計算するためにコサイン類似度などを用います。コサイン類似度は、「角度」のようなもので類似度を計算する仕組みです。しかし、距離をベースに類似度を計算するKNNと同様、次元の呪いの影響を受けてしまいます。KNNと次元の呪いについては、下記記事を参考にしてください。

コサイン類似度と次元の呪い

簡単ですが、協調フィルタリングにおける次元の呪いについて説明します。次元とは特徴量の数だと思ってください。特徴量というのは、データの属性のことです。人間の属性としては、年齢・身長・体重などがあります。商品の属性としては、カテゴリー・大きさ・価格などがそうですね。コサイン類似度で似ているかどうかを判定した場合、特徴量の数が少ないと類似度が高くなる傾向があり、特徴量の数が多いと類似度が低くなる傾向があるのです。したがって、次元の呪いを回避するための工夫が必要となります。
そのため、次元の呪いを回避したMatrix Factorizationなどの推薦アルゴリズムが登場しています。
PythonとKNN(K近傍法)によるアイテムベース協調フィルタリングの実装
ここからはおすすめの映画をレコメンド(推薦)するAIを作成します。具体的には、プログラミング言語Pythonを用いて、アイテムベースの協調フィルタリングを実装します。アルゴリズムとして、KNN(K近傍法)を利用します。KNNの詳細に関しても、下記記事を参考にしてください。
MovieLensというサイトから映画の推薦システムに利用できる「ml-latest-small.zip」というデータをダウンロードして使用します。このCSVファイルにある、ユーザーID、映画ID、映画の評価の3列のみを利用します。なお、映画の評価は0.5~5.0点の0.5点刻みです。
映画の類似度=評価の類似度として、ある映画を入力して、それと似た評価の映画をレコメンドするようにします。
#必要なモジュールをインポート
import pandas as pd
import numpy as np
from scipy.sparse import csr_matrix
from sklearn.neighbors import NearestNeighbors
#pandasライブラリで読み込み。自動的にカラム名設定。
df = pd.read_csv("ratings.csv", sep=",")
#最初の0~2列目までを利用(ユーザーID、映画ID、評価の3列を利用)
df = df.iloc[:,0:3]
#疎行列(行列の中身が0ばかりの行列)に変換。行名が映画のID、列名がユーザーID、行列の中身が評価
df_piv = df.pivot(index= "movieId",columns="userId",values="rating").fillna(0)
#scikit-learnでの処理が速くなるデータ形式に変換
df_sp = csr_matrix(df_piv.values)
#KNNのインスタンス化。評価方法をコサイン類似度に設定。bruteは総当り方式。
rec = NearestNeighbors(n_neighbors=10,algorithm= "brute", metric= "cosine")
# KNNで訓練
rec_model = rec.fit(df_sp)
# 映画ID「100」に対するおすすめの映画10個を類似度(下記のdistances)が近い順番に表示。
#下記のindicesは各点から近い順にインデックスが入っており、行iには点iに近い順にインデックスが入っている。
# 下記のn_neighbors=11は自身を含めて11個のデータを取り出す。
Movie = 100#任意の好きな映画ID
distance, indice = rec_model.kneighbors(df_piv.iloc[df_piv.index== Movie].values.reshape(1,-1),n_neighbors=11)
for i in range(11):#i=0は映画ID100のことであり、i=1~10までは評価が似ている映画のこと。
if i == 0:#i=0はID100のこと。
print("映画ID{}を見た人におすすめの映画IDは以下です。".format(Movie))
else:
print("{0}: {1}".format(i,df_piv.index[indice.flatten()[i]]))#似ている順に映画IDを表示。
上記コードを実行すると、以下のような結果を得られます。
「映画ID100を見た人におすすめの映画IDは以下です。
1: 26
2: 354
3: 1006
4: 61
5: 667
6: 74
7: 981
8: 1082
9: 881
10: 76」
ということで、ある映画と似た評価の映画をおすすめするAIを作成することができました。
ユーザーベース協調フィルタリングの実装
おおむね流れはアイテムベースと同じです。アイテムベースのときと同じデータ、同じアルゴリズム(KNN)で実行します。ユーザー類似度が近いユーザーを見つけ、そのユーザーが最も評価している映画を3つ提案します。
#必要なモジュールをインポート
import pandas as pd
import numpy as np
from scipy.sparse import csr_matrix
from sklearn.neighbors import NearestNeighbors
#pandasライブラリで読み込み。自動的にカラム名設定。
df = pd.read_csv("ratings.csv", sep=",")
#最初の0~2列目までを利用(ユーザーID、映画ID、評価の3列を利用)
df = df.iloc[:,0:3]
#疎行列(行列の中身が0ばかりの行列)に変換。行名がユーザーID、列名が映画のID、行列の中身が評価
df_piv = df.pivot(index= "userId",columns="movieId",values="rating").fillna(0)
#scikit-learnでの処理が速くなるデータ形式に変換
df_sp = csr_matrix(df_piv.values)
#KNNのインスタンス化。評価方法をコサイン類似度に設定。bruteは総当り方式。
rec = NearestNeighbors(n_neighbors=10,algorithm= "brute", metric= "cosine")
# KNNで訓練
rec_model = rec.fit(df_sp)
User = 100#ユーザーID100に似ているユーザーを見つける。
distance, indice = rec_model.kneighbors(df_piv.iloc[df_piv.index== User].values.reshape(1,-1),n_neighbors=2)
for i in range(2):#i=0はユーザーID100のことであり、i=1は最も似ているユーザーのこと。
if i == 0:#ユーザーID100のこと。自分自身。
print("ユーザーID:{0}に似たユーザーID,(おすすめ映画ID,評価)は以下になります。".format(User))
else:
print('ユーザーID:{0} '.format(df_piv.index[indice.flatten() [i]]))
rec_movie = df_piv[df_piv.index[indice.flatten() [i]]]
rec_movie_sort = sorted(rec_movie.items(), reverse=True, key=lambda x:x[1])#reverse→降順、辞書のvalueをkeyにソート
rec_movie_3 = rec_movie_sort[0:3]#評価の高い映画を3つ抽出
print(rec_movie_3)
上記コードを実行すると、結果は以下となります。
「ユーザーID100に似たユーザーID,(おすすめ映画ID,評価)は以下になります。
ユーザーID:357
[(8, 5.0), (38, 5.0), (66, 5.0)]」
以上で協調フィルタリングによるアイテムベースとユーザーベースのレコメンドエンジンが完成しました。