サポートベクターマシン(SVM)とランダムフォレストの異常値検出版といえるのがOne Class SVM(OC-SVM)とアイソレーションフォレストです。SVMとランダムフォレストの基礎から学びたい人は以下の記事を参照してください。


この記事では、OC-SVMとアイソレーションフォレストの概要、Pythonによる簡単な実装例を紹介します。Pythonのscikit-learnというライブラリを活用すると簡単に実装できます。

目次
異常値検出はどんなビジネスに活用できるのか?
クレジットカードの不正取引を検出したり、工場で熱やサイズの異常を検知したりすることができます。他にも故障を発見したり、音の異常を見抜いたりなど、活用シーンが非常に多いです。
One Class SVM(OC-SVM)とアイソレーションフォレストは教師なし学習
SVMとランダムフォレストが教師あり学習だったのに対して、OC-SVMとアイソレーションフォレストは教師なし学習です。そのため、「正常」「異常」などの正解ラベルがなくても異常値検出を行うことができます。ラベルの設定の手間が不要である点は非常に魅力的です。
SVMを異常値検出に応用したOC-SVM
一般に、多数の正常値データが得られる一方、異常値データは多く手に入りません。そのため、正常値データのみを学習することでその正常値データの特徴をつかみ、その特徴とは異なる異常値データを判別します。それを実現するのがOC-SVMなのです。
ここからはOC-SVMの説明をしますが、図を見るとイメージをつかめると思いますので、下図を見ながら読み進めてください。OC-SVMは、正常値データをグループ1、原点のみをグループ2とし、SVMと同様にカーネル法で高次元の空間に変換します。このとき、カーネル法により都合の良い空間に変換されており、グループ1は原点(グループ2)から離れたところに位置しています。そして、SVMのマージン最大化と同様に、原点からの距離が最大となる境界を求めます。そうすると都合が良いことに、異常値データを入力すると、そのデータは変換された空間内で原点に近いところに集まります。これにより原点に近い(境界の原点側にある)データを異常値データとみなすことができます。

PythonとOC-SVMによる簡単な外れ値検知の実装

OC-SVMの重要なハイパーパラメータはnuです。トレーニングを行うデータは常にきれいなデータとは限らないため、トレーニングデータの中にある異常値の割合を設定する必要があり、これがnuです。今回は0~1の値の乱数を99個作成し、そこに異常値を1個加えた100個のデータでトレーニングを行います。トレーニングデータ100個のうち1個が異常値なので、nu=0.01とします。また、予測の実行結果は、1が正常値、-1が異常値となります。
#必要なモジュールをインポート import numpy as np from numpy.random import rand from sklearn.svm import OneClassSVM #0~1の値を取る乱数を99個作成 random_train = rand(99) #トレーニングデータに潜ませる異常値データ ab_train= 1.5 #上記のデータを結合し、100行1列のデータに整形 X_train = np.append(random_train,ab_train).reshape(-1,1) #テストデータ。5個のデータがあり、最後のデータ「2」が異常値 X_test =np.array([0.5,0.7,0.3,0.2,2]).reshape(-1,1) #OC-SVMをインスタンス化。トレーニングデータには1個異常値が含ませているので、nu=0.01とする clf = OneClassSVM(nu = 0.01,gamma='auto') #トレーニングの実行 clf.fit(X_train) #予測の実行 pred = clf.predict(X_test) #-1(異常値)となったデータのインデックスを表示 np.where(pred < 0) #インデックス4(最後)のデータとなり、確かに異常値を判定できている。
アイソレーションフォレストの概要
詳細を厳密に語るのではなく、ざっくりとイメージを理解できるよう説明します。
ランダムフォレストも異常値検出に用いることができ、それをアイソレーションフォレストと呼びます。これらはともに決定木をベースとしたアルゴリズムです。決定木を異常値検出にどう用いるかというと、「異常値データはすぐに決定木のリーフノード(これ以上分割できないノード)になる」ことを利用しています。
ランダムフォレストのように多数の決定木を発生させますが、その際にランダムに特徴量を選択し、ランダムに特徴量の分岐ポイントを選択します。この「ランダムに分岐ポイントを選択する」という点が重要です。ランダムに分岐ポイントを選んだとき、異常値データは正常値データより早くリーフノード(これ以上分割できないノード)となる確率が高いからです。多数の決定木を作成し、各データがリーフノードとなるまで木を成長させます(途中で打ち切る場合もあります)。そして、それぞれのデータの木の深さの平均値を算出し、平均値が小さいデータほど異常を示していると判断します。
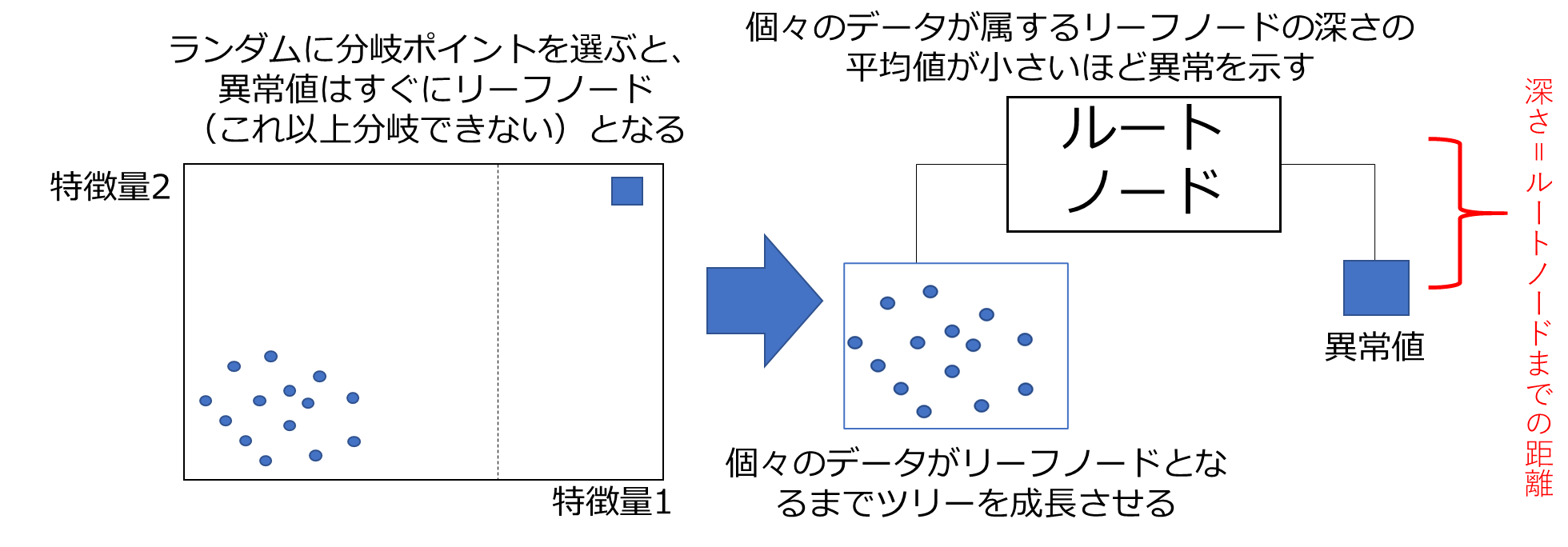
Pythonとアイソレーションフォレストによる異常値検出の簡単な実装
アイソレーションフォレストはOC-SVMとほぼ同じコードで実装できます。OC-SVMのnuに対応したハイパーパラメータとして、アイソレーションフォレストではcontaminationというものがあります。予測の実行結果が、正常値が1、異常値が-1となる点も同じです。
#必要なモジュールをインポート import numpy as np from numpy.random import rand from sklearn.ensemble import IsolationForest #0~1の値を取る乱数を99個作成 random_train = rand(99) #トレーニングデータに潜ませる異常値データ ab_train= 1.5 #上記のデータを結合し、100行1列のデータに整形 X_train = np.append(random_train,ab_train).reshape(-1,1) #テストデータ。5個のデータがあり、最後のデータ「2」が異常値 X_test =np.array([0.5,0.7,0.3,0.2,2]).reshape(-1,1) #アイソレーションフォレストをインスタンス化。OC-SVMのnuに対応するのがcontamination。何も設定しない場合は"auto"となる。 clf = IsolationForest(contamination=0.01) #トレーニングの実行 clf.fit(X_train) #予測の実行 pred = clf.predict(X_test) #-1(異常値)となったデータのインデックスを表示 np.where(pred < 0) #インデックス4(最後)のデータとなり、確かに異常値を判定できている。
まとめ
架空のデータですが、OC-SVMとアイソレーションフォレストともに簡単に実装できました。scikit-learnは非常に便利なライブラリですね。異常値検出は非常に応用範囲が広く、実際のビジネスでも多く導入されています。
ここまで長文を読んでいただきありがとうございました。