





機械学習とは、データから学習(トレーニング)してルールやパターンを発見するための技術であり、現在のAIのベースになっているものです。たとえば、犬と猫の画像データを学習して、新しい画像が与えられたときにそれが犬か猫か判断できるようになります。
その機械学習にはさまざまなアルゴリズムがありますが、大きく分けて線形モデルと非線形モデルがあります。そして、これを区別することが脱機械学習初心者に向けた第一歩となります。
まずは線形・非線形モデルの違いと使い分けについて説明し、後半でPythonプログラミング言語による実装例を紹介します。
目次
線形モデルとは?
線形モデルは、主に直線(1次関数)で数値を予測したり、直線を引いてデータを分類することと考えるとわかりやすいはずです。数値予測のことを回帰、データをグループに分けることを分類といいます。
したがって、株価を予測することは回帰ですし、画像データを犬と猫に分けることなどが分類になります。
下図は線形モデルにおける回帰と分類のイメージです。回帰の場合は、数学で習うような関数で数値を予測することになります。分類の場合、データが直線よりも上にあるか下にあるかでグループを判定します。

非線形モデルとは?
非線形モデルとは、直線ではなく曲線を用いるものです。イメージとしては、下記のような具合です。直線が曲線になっただけですよね。

次元が高くなった場合の呼称について
2次元の場合は直線や曲線と言いますが、3次元の場合は「平面」や「曲面」と呼びます。それ以上の場合は「超平面」や「超曲面」などと呼びます。「超平面」というおおげさな名前ですが、直線や平面の次元が高くなったものと考えれば問題ありません。
例:ワインの質を予測する線形モデル
まず、線形モデルの例を挙げましょう。ワイン好きの経済学者オーリー・アッシェンフェルター氏は、ワインの質を予測する回帰式を導きました。それは以下のようなものです。
ワインの質 = 12.145+0.00117×冬の降雨量+0.0614×育成期平均気温-0.00386×収穫期降雨量
これを\(y\)と\(x\)を用いて書き直すと
\(y=12.145+0.00117x_1+0.0614x_2-0.00386x_3\)
ここで\(y\)を目的変数、\(x\)を説明変数といいます。特に機械学習やAIの分野では、説明変数のことを特徴量と呼ぶことが多いです。
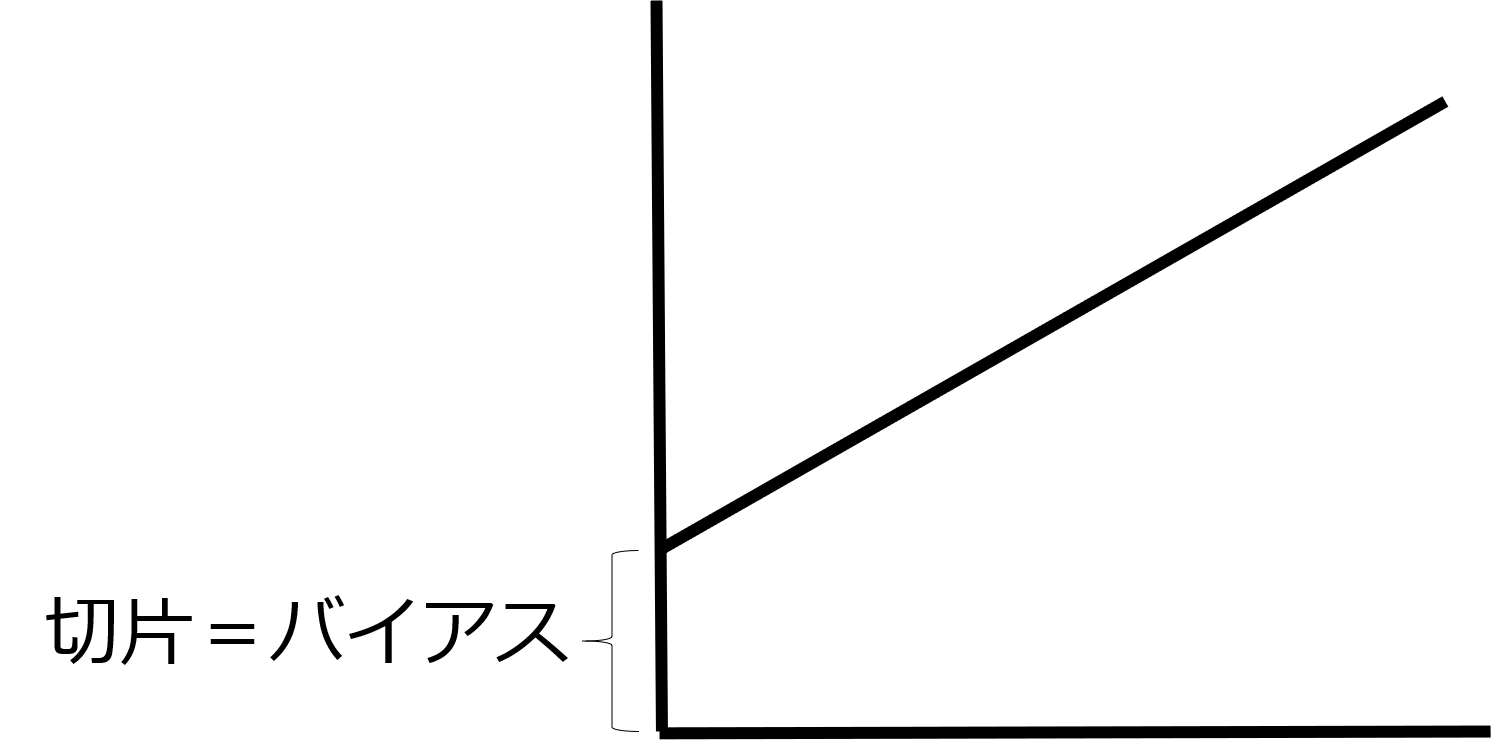
つまりこの式は、ワインの質は冬の降雨量と育成期平均気温、収穫期降雨量という特徴量を用いて予測できると主張しています。ちなみに、上記式の12.145は関数の言葉では切片、機械学習の言葉ではバイアスと呼びます。切片(バイアス)のイメージは下図のようになります。
線形モデルの注意点
ただ、線形モデルにおいては、すべての特徴量が独立である(関係がない)と仮定されています。たとえば、非喫煙者のグループでは飲酒量と肺ガンリスクには関連はありません。ところが、喫煙グループでは肺ガンのリスクが高く、飲酒量が多い人はさらにリスクが高くなるとわかっています。飲酒だけでは肺ガンのリスクを高めませんが、飲酒とタバコがセットになることで肺ガンリスクを高めてしまうのです。このように、特徴量同士が影響を与えあっている場合がありますが、そのような関係を線形モデルが読み取ってくれることはないのです。ちなみに、このような特徴量間の相互作用を「交互作用」と呼び、考慮が必要です。
線形モデルが重要な理由

「直線で予測するなんて精度が低いのではないか? 曲線で予測すべきだ」と思われるかもしれません。確かに直感的に考えると、直線で予測や分類を行う線形モデルで高い精度が出るとは思えません。
ところが、データ数が少ない場合には直線で予測した方が良い場合も多いのです。したがって、線形モデルは現在のデータサイエンスにおいても非常に重要な考え方なのです。
非線形モデルの欠点
非線形モデルの問題は、線形モデルよりも学習(トレーニング)データに過剰に適合してしまうことです。これを過学習と呼びます。特に、データ数が少ない場合に学習(トレーニング)した場合は顕著で、未知のデータの予測にはまったく使えないということがあります。
使い分けるサンプル数(データ数)の目安
線形と非線形モデルの学習(トレーニング)に用いるサンプル数(データ数)の目安が気になりますよね? これに対しては、実は明確な答えというものがありません。ただ、10万ほどのサンプル数なら線形モデルの方が精度が高い場合もあります。したがって、線形モデルと非線形モデルの両方で学習を行い、精度を比較しながら最適なモデルを選択することになります。
ロジスティック回帰という線形モデルによるPythonコード例
今からPythonというプラグラミング言語を用いて、線形モデルを用いた分類予測を行います。scikit-learnというデータサイエンス用のライブラリーの中にある、ワインの品質予測に関するデータを使いましょう。ワインの色やアルコール濃度、ポリフェノール量などから、専門家のワイン品質評価を模倣する線形モデルを作成します。
今回は、あらかじめデータに標準化という処理を行っておきます。標準化とは、データの単位を合わせることです。身長と体重の場合、171cm、59kgと単位が違いますよね。身長と体重が1増加することによる影響は、身長と体重で大きく変わります。したがって、標準化を行うことで単位を揃えます。
線形モデルとしてロジスティック回帰というアルゴリズムを適用します。ややこしいことに、回帰という名前が付いていますが、分類のために用います。
#必要なモジュールをインポート from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import StandardScaler from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score #scikit-learn内にあるワインの品質判定用データセットをwineという変数に代入。 wine = load_wine() #Xにワインの特徴量を代入。特徴量は、ここではアルコール濃度や色などwineの属性データのこと。 X=wine.data #yにワインの目的変数を代入。目的変数は、ここでは専門家によるワインの品質評価結果のこと。 y=wine.target #トレーニングデータとテストデータに分割。 #トレーニングデータで学習を行い、テストデータでAIが実際に使えるかの精度検証。テストデータは全体の3割に設定。 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) #標準化を実行するためのStandardScalerをインスタンス化(実体化)。fitで訓練データを標準化する際の準備。 scaler = StandardScaler() scaler.fit(X_train) #ロジスティック回帰をインスタンス化(実体化)。 clf = LogisticRegression() #transformで標準化を実際に行い、そのデータに対してロジスティック回帰による学習を行う clf.fit(scaler.transform(X_train), y_train) #テストデータにも標準化を実行し、predict(予測)を行う y_pred = clf.predict(scaler.transform(X_test)) #正解率の算出。予測データと正解データを比較してAIの精度検証を行う。 accuracy_score(y_test,y_pred) #専門家とAIの予測の一致率は100%となった
ロジスティック回帰という線形モデルで100%という高い一致率となりました。ただし、このような高すぎる精度はあまり信じないようにしましょう。「これで専門家の予測と完璧に一致するAIが作れた!」と思わない方が賢明です。
決定木という非線形モデルによるPythonコード例
次に、ロジスティック回帰の代わりに決定木という非線形のアルゴリズムで予測をしたいと思います。scikit-learnという便利なライブラリーのおかげで、少しコードをいじるだけで予測を行えます。さきほどのコードとの違いは、以下の2行だけです。
from sklearn.tree import DecisionTreeClassifier clf = DecisionTreeClassifier()
決定木は標準化をしなくても問題ないのですが、純粋に線形と非線形モデルの精度を比較したいので、標準化したデータで学習を実行します。
#必要なモジュールをインポート from sklearn.tree import DecisionTreeClassifier from sklearn.preprocessing import StandardScaler from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score #scikit-learn内にあるワインの品質判定用データセットをwineという変数に代入。 wine = load_wine() #Xにワインの特徴量を代入。特徴量は、ここではアルコール濃度や色などwineの属性データのこと。 X=wine.data #yにワインの目的変数を代入。目的変数は、ここでは専門家によるワインの品質評価結果のこと。 y=wine.target #トレーニングデータとテストデータに分割。 #トレーニングデータで学習を行い、テストデータでAIが実際に使えるかの精度検証。テストデータは全体の3割に設定。 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) #標準化を実行するためのStandardScalerをインスタンス化(実体化)。fitで訓練データを標準化する際の準備。 scaler = StandardScaler() scaler.fit(X_train) #決定木をインスタンス化(実体化)。 clf = DecisionTreeClassifier() #transformで標準化を実際に行い、そのデータに対して決定木による学習を行う clf.fit(scaler.transform(X_train), y_train) #テストデータにも標準化を実行し、predict(予測)を行う y_pred = clf.predict(scaler.transform(X_test)) #正解率の算出。予測データと正解データを比較してAIの精度検証を行う。 accuracy_score(y_test,y_pred) #専門家とAIの予測の一致率は約92.6%となった
作成したAIと専門家の予測の一致率は92.6%となりました。結果として線形モデルの方が高い精度となりました。実は、今回のワインデータのサンプル数(データ数)は178個でした。サンプル数が少ないため、線形モデルの方が良さそうですね。
まとめ
ここまで、線形モデルと非線形モデルの違いについて見てきました。勉強を初めて間もないころは、「非線形モデルの方が精度が出るはずだ!」と思ってしまいがちです。しかし、線形モデルが活躍する瞬間も非常に多いです。両方のモデルが大事だということをぜひ覚えておいてください。
どうもありがとうございました。またお会いしましょう!